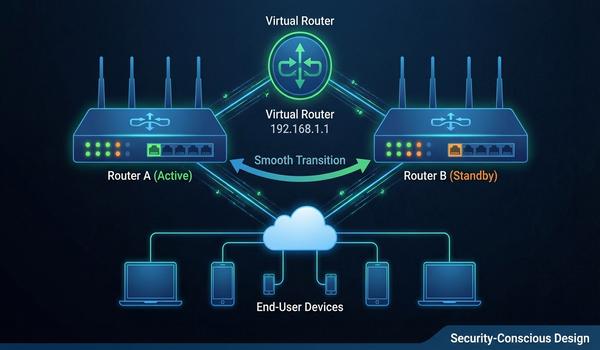
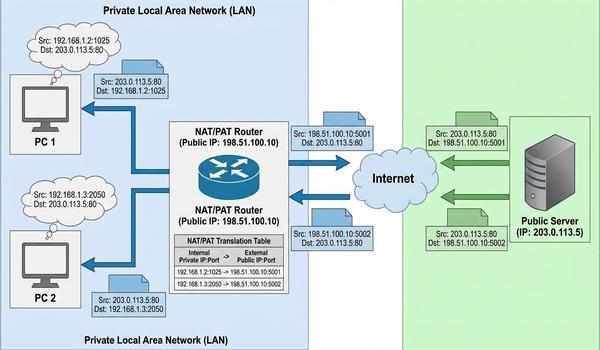
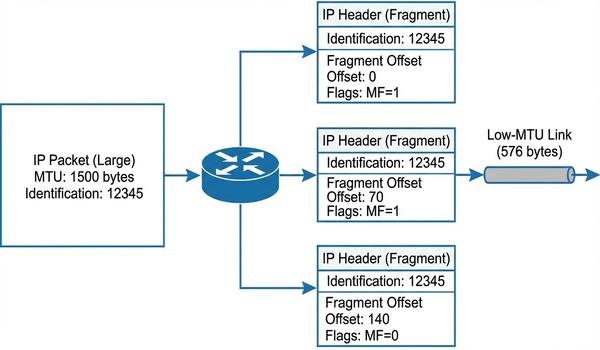
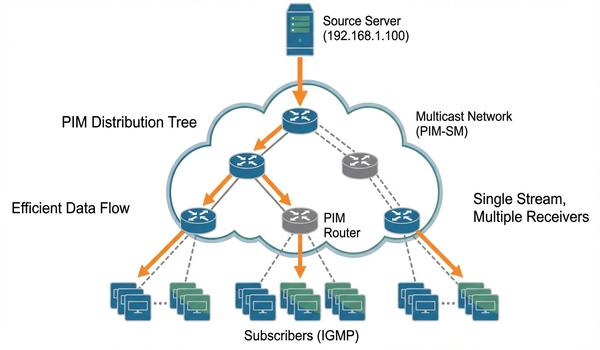
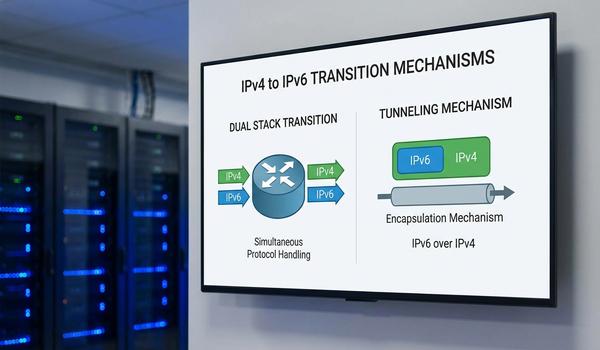
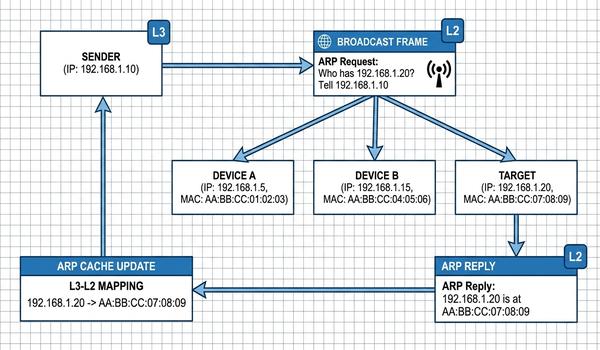
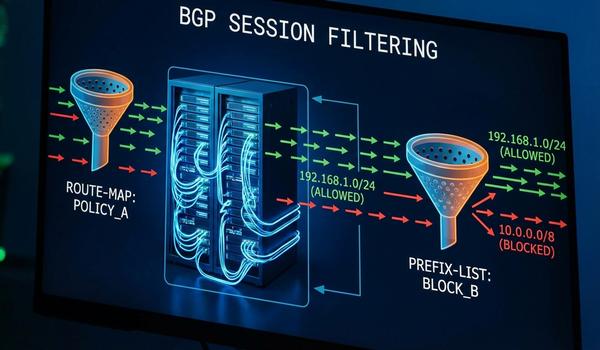
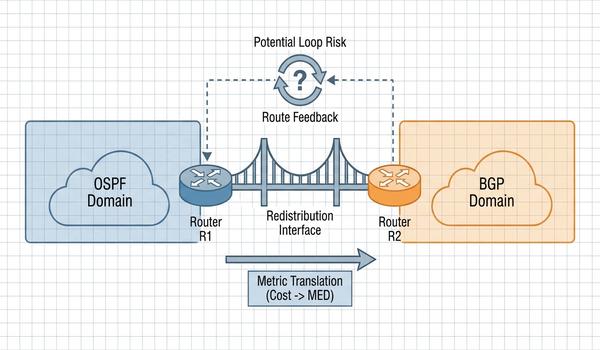
Warstwa trzecia modelu OSI - adresowanie logiczne
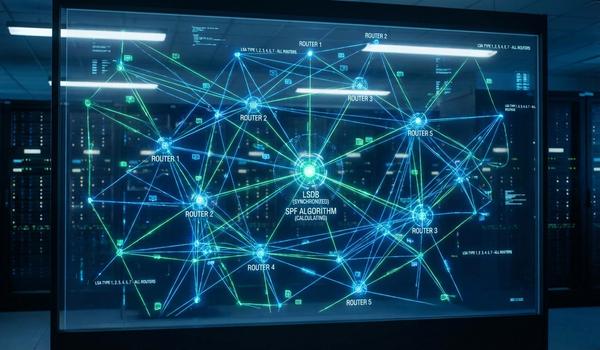
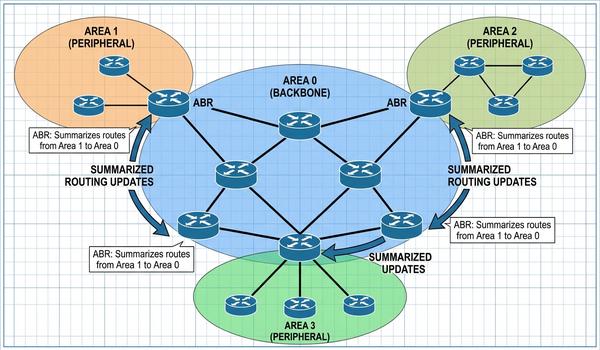
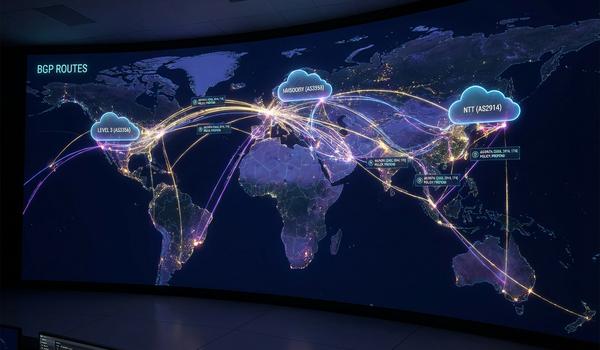
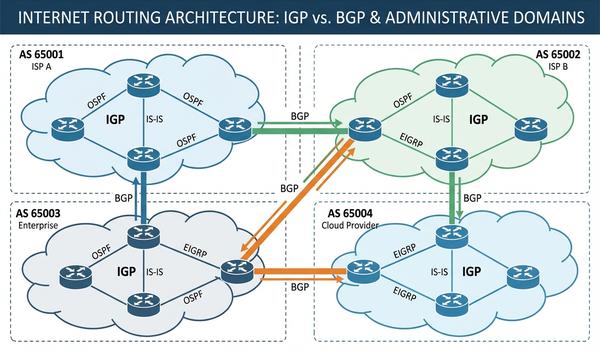
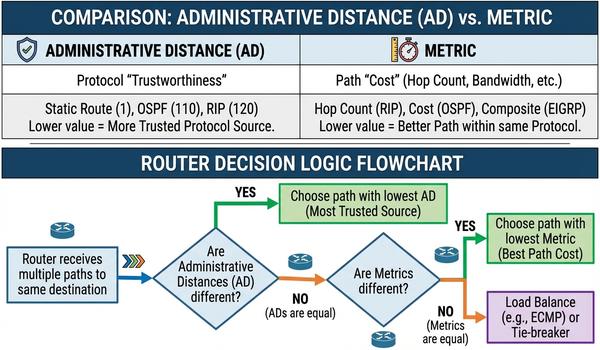
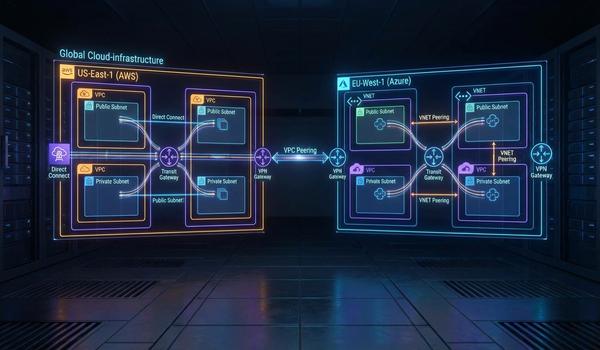
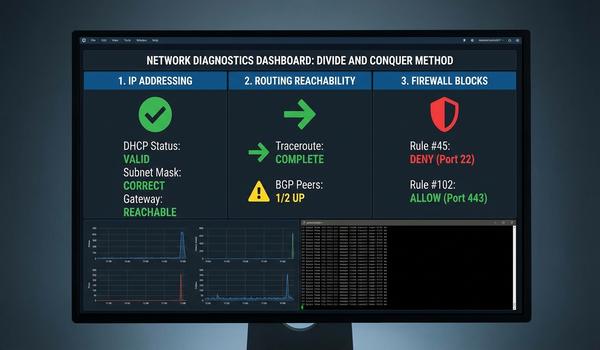
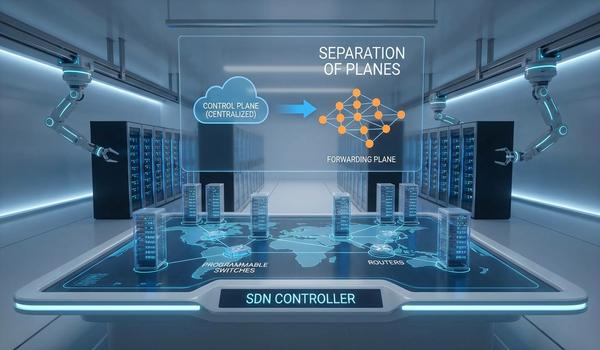
Warstwa sieciowa, znana również jako warstwa trzecia modelu OSI, jest kluczowym elementem umożliwiającym komunikację między systemami w różnych segmentach fizycznych. Podczas dzisiejszego wykładu skupimy się na protokole IP, który stanowi fundament adresowania i routingu w globalnej sieci Internet. Głównym zadaniem tej warstwy jest zapewnienie mechanizmów pozwalających na dostarczenie pakietów danych od źródła do celu przez wiele węzłów pośrednich. W przeciwieństwie do warstwy drugiej, operujemy tutaj na adresach logicznych, które są niezależne od sprzętu fizycznego. Przeanalizujemy strukturę nagłówków IP oraz zasady, którymi kierują się routery podczas wyboru najlepszej ścieżki transmisji. Zrozumienie tych mechanizmów jest niezbędne dla każdego inżyniera projektującego skalowalne i wydajne sieci korporacyjne. Poprawna konfiguracja warstwy trzeciej decyduje o zasięgu i stabilności całej infrastruktury teleinformatycznej.